27/2/2026
architecture
The Architecture: Why It Matters
If you take a look at where the world is headed, it’s pretty obvious: unstructured data has won.
Documents, media, logs, embeddings, AI artifacts—it all needs to live somewhere. We need durability, governance, and global access. When you zoom out, you can see the entire industry converging on object storage as the only abstraction capable of carrying that weight.
That makes sense to me. But here’s the thing: I never believed object storage, by itself, was the whole answer.
It solves a big part of the problem, but it doesn't solve the structural foundation underneath it. Today, I want to pull back the curtain on what we realized the moment we committed to building on object storage—and why most systems "flinch" when they get too big.
Once we accepted object storage as the standard, the next hurdle was performance. Specifically, performance at scale.
When I say scale, I’m talking about two distinct vectors:
You can scale vertically for a while—bigger machines, faster CPUs, denser disks—but that road has a dead end. Eventually, you have to go horizontal. You need more nodes, more disks, and more parallel network paths.
We chose horizontal scaling deliberately because it’s the only way to handle both capacity and bandwidth long-term. But the moment you go horizontal, you run into a very uncomfortable question: Where does the data live, and how do you find it?
Everyone understands sharding. You distribute objects across nodes, you get parallelism, and you get availability. That part isn't controversial.
What is under-discussed is metadata.
The moment you shard, you have to track where everything went. Suddenly, your metadata becomes its own complex system. I started asking the hard questions:
We looked at plenty of architectures. Some use expensive, centralized clusters; others use complex rebalancing logic. But most share a similar trade-off: at a certain scale, metadata becomes expensive, fragile, or slow. You might get a "fast" lookup, but you’ve introduced an extra network hop before you even see the first byte of data.
If your metadata service doesn’t scale at the same rate as your data, you’ve built a ceiling.
We made a decision early on: Metadata could not be the bottleneck. It had to scale horizontally, just like the data. We set some aggressive targets:
These sound like simple bullets, but in practice, you’re constantly juggling speed versus coordination. To solve this, we didn't just tweak an existing pattern. We built a new database paradigm specifically for this problem.
That foundation became PixelDB.
I care deeply about time-to-first-byte. I didn't want a "layered" system where you resolve metadata, then location, then shard mapping, then—finally—pull data.
We validated a protocol called uRPC specifically to guarantee a single logical hop to your object. No layered trees, no opaque coordination paths. At scale, that matters more than people realize.
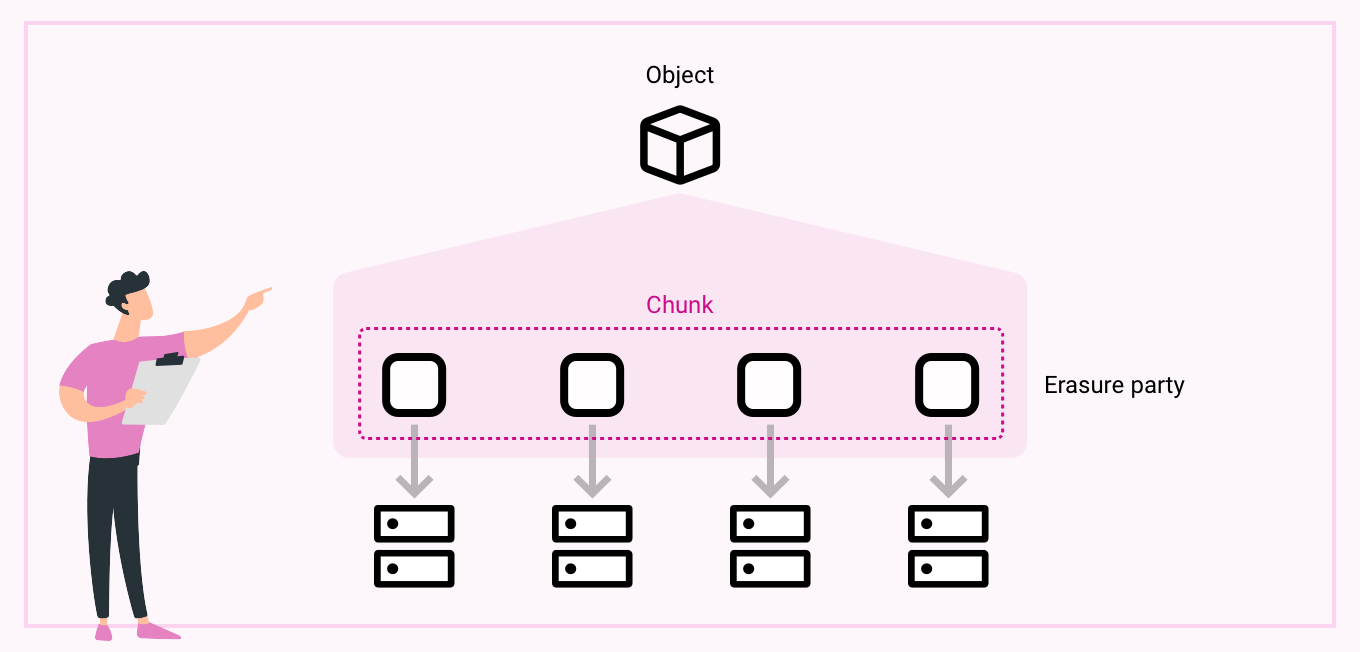
For availability, we chose erasure coding (specifically a 12/8 model: 12 fragments written, 8 required to reconstruct).
This gives us incredible durability and only about 1.5x overhead compared to the traditional 3x replication. But here’s the cool part: erasure coding didn’t just give us safety; it gave us speed.
Because shards are spread across many nodes, a single object is dynamically distributed. Reads aggregate bandwidth from across the cluster. Instead of hotspots, you get amplification. Durability and throughput actually reinforce each other.
We were obsessive about keeping metadata lean. Objects are directly referenced—no heavy indirection trees. This keeps memory usage predictable and lookups lightning-fast.
More importantly, our architecture follows a simple rule:
There’s no heavyweight cluster manager or complex election logic sitting in the "hot path" slowing down your access. This simplicity allows the system to stretch to thousands of nodes without becoming fragile.
At the end of the day, we were solving for long-term supportability. We didn't want a system that works until it becomes successful; we wanted one that works because it becomes successful.
PixelDB is the foundation that lets FastS³ scale without flinching. By combining high redundancy, distributed metadata, and single-hop lookups, we’ve built the bedrock for everything else—AI pipelines, global governance, and high-concurrency workloads.
We built PixelDB because I wanted a foundation that stays solid under stress. What we’re building on top of it now is where the real magic happens.

